 furas.pl
furas.plPython Unicode - decode & encode
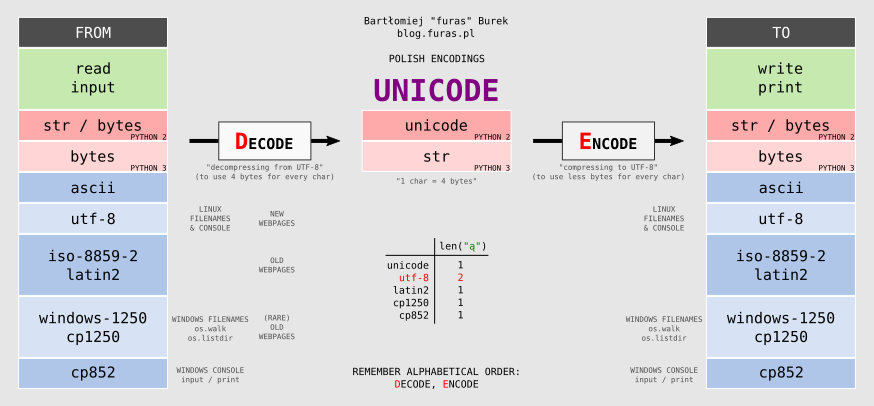
--------------+ +--------------
FROM | | TO
--------------+ +--------------
read | | write
input | | print
--------------+ +--------------
| |
str | --- [d]ecode ---> UNICODE --- [e]ncode ---> | str
| |
--------------+ +--------------
ascii | | ascii
--------------+ +--------------
utf-8 | | utf-8
--------------+ +--------------
iso-8859-2 | | iso-8859-2
latin2 | | latin2
--------------+ +--------------
windows-1250 | | windows-1250
cp1250 | | cp1250
--------------+ +--------------
cp852 | | cp852
--------------+ +--------------
Można zapamiętać dzięki kolejności alfabetycznej: [d]ecode, [e]ncode
Zamiana tekstu na prawdziwy Unicode, który nie jest tekstem Unicode (nie ma prefixu u) a mimo wszystko zawiera kody Unicode (np. \u041d)
"\u041d\u0438\u043a\u043e\u043b\u0430".decode('unicode-escape') # bez przedrostku 'u'
u"\u041d\u0438\u043a\u043e\u043b\u0430" # z przedrostkiem 'u'
i teraz można dopiero to zamienić na 'utf-8' i wypisać na konsoli Linuxa
print u"\u041d\u0438\u043a\u043e\u043b\u0430".encode('utf-8')
Никола
Windows może wymagać zamiany nie na utf-8 ale na cp852 - lub na coś innego o ile obsługuje Cyrylicę.
Kodowanie polskich znaków (pl.wikipedia)
UTF-8 (pl.wikipedia)
UTF-8 (en.wikipedia)
Unicode (pl.wikipedia)
Unicode (en.wikipedia)
List of Unicode characters (en.wikipedia)
If you like it
 Buy a Coffee
Buy a Coffee